📖 Table of contents 📖
1 - Code datasets
2 - Model architecture
3 - Model evaluation
4 - Code generation
For each section, you can choose to visualize the information of 4 code generation models:
In section 4, you get to prompt the models and test their code generation capacities ✨!
Code generation with 🤗
This is an interactive blog that provides an overview of open-source language models for code generation. This post presents:
- code datasets
- model architectures
- model evaluation
We also give examples and tips to use the 🤗 Hub for this task. At the end of this blog, you will find a demo to test and compare code generation across multi-billion parameter code models directly in the browser! Here's a small teaser ✨:
def print_hello_world():
[interactive button]
def print_hello_world():
print("Hello, world!")
Introduction
The application of language models to code generation has sparked great interest recently. You have probably heard of Codex, the model behind Github Copilot, or AlphaCode for competition-level programming. These models aren't open-source, and it is hard to reproduce them with a limited budget and incomplete information about their training. The ML community has luckily contributed some code models to allow for further research.
However, it can be easy to get lost between models. At Hugging Face we aim to democratize ML and centralize all information in the 🤗 ecosystem to make the usage of open-source tools easier and more efficient. Code models aren't an exception, you can find all open-source models on the Hub, with several code datasets and evaluation metrics. In this blog we will give an overview of these tools and how to use them.

1 - Code datasets
Most code models are trained on data from public software repositories hosted on GitHub. Some also include code coupled with natural text from platforms such as Stack Overflow. Additional datasets can be crafted based on the target task of the model. Alphacode, for instance, was fine-tuned on CodeContests, a competitive programming dataset for machine-learning. Another popular dataset is The Pile, which is a large corpus containing both natural language texts and code from different sources such as StackExchange dumps and popular (>100 stars) GitHub repositories. It can be efficient for models intended to do translation from natural text to code or the opposite, it was used in CodeGen for instance.
Below is the distribution of the pretraining data size of some code models, we provide model-specific information for open-source models later in this section:
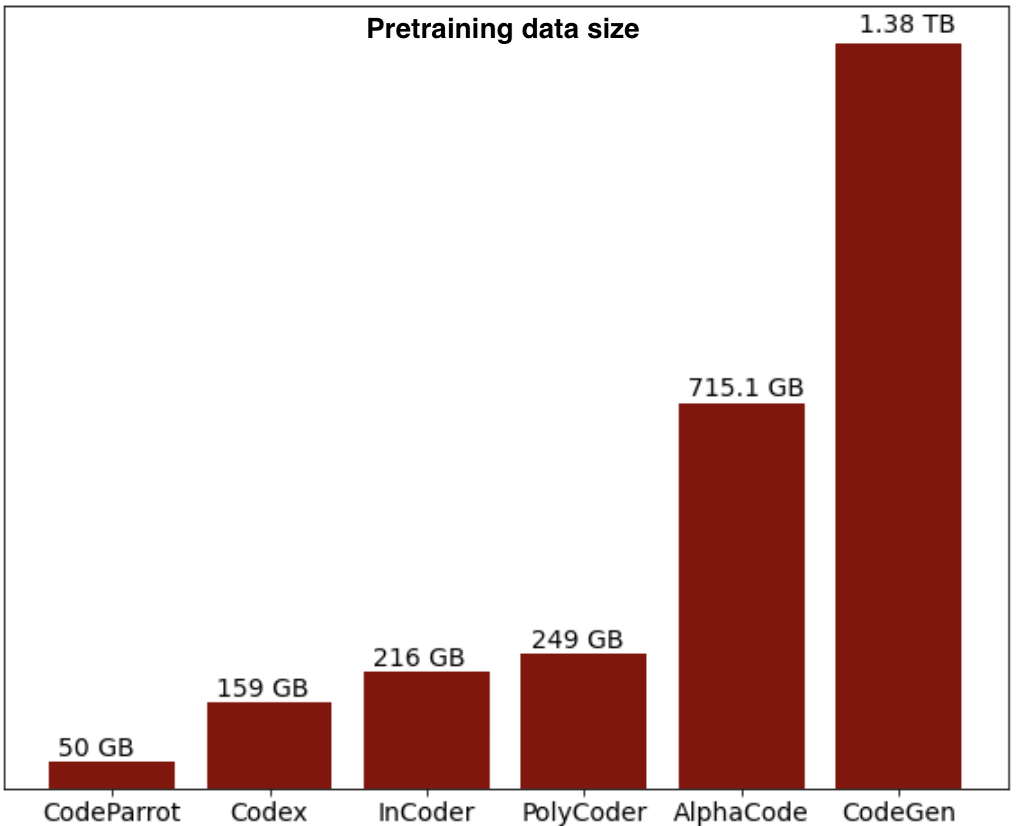
Some other useful datasets that are available on the 🤗 Hub are CodeSearchNet, a corpus of 2 milllion (comment, code) pairs from open-source libraries hosted on GitHub for several programming languages, and Mostly Basic Python Problems (mbpp), a benchmark of around 1,000 crowd-sourced Python programming problems, for entry level programmers, where each problem consists of a task description, code solution and 3 automated test cases, this dataset was used in InCoder evaluation in addition to HumanEval that we will present later. You can also find APPS, a benchmark with 10000 problems consisting of programming questions in English and code solutions in Python, this dataset was also used in Codex evaluation along with HumanEval.
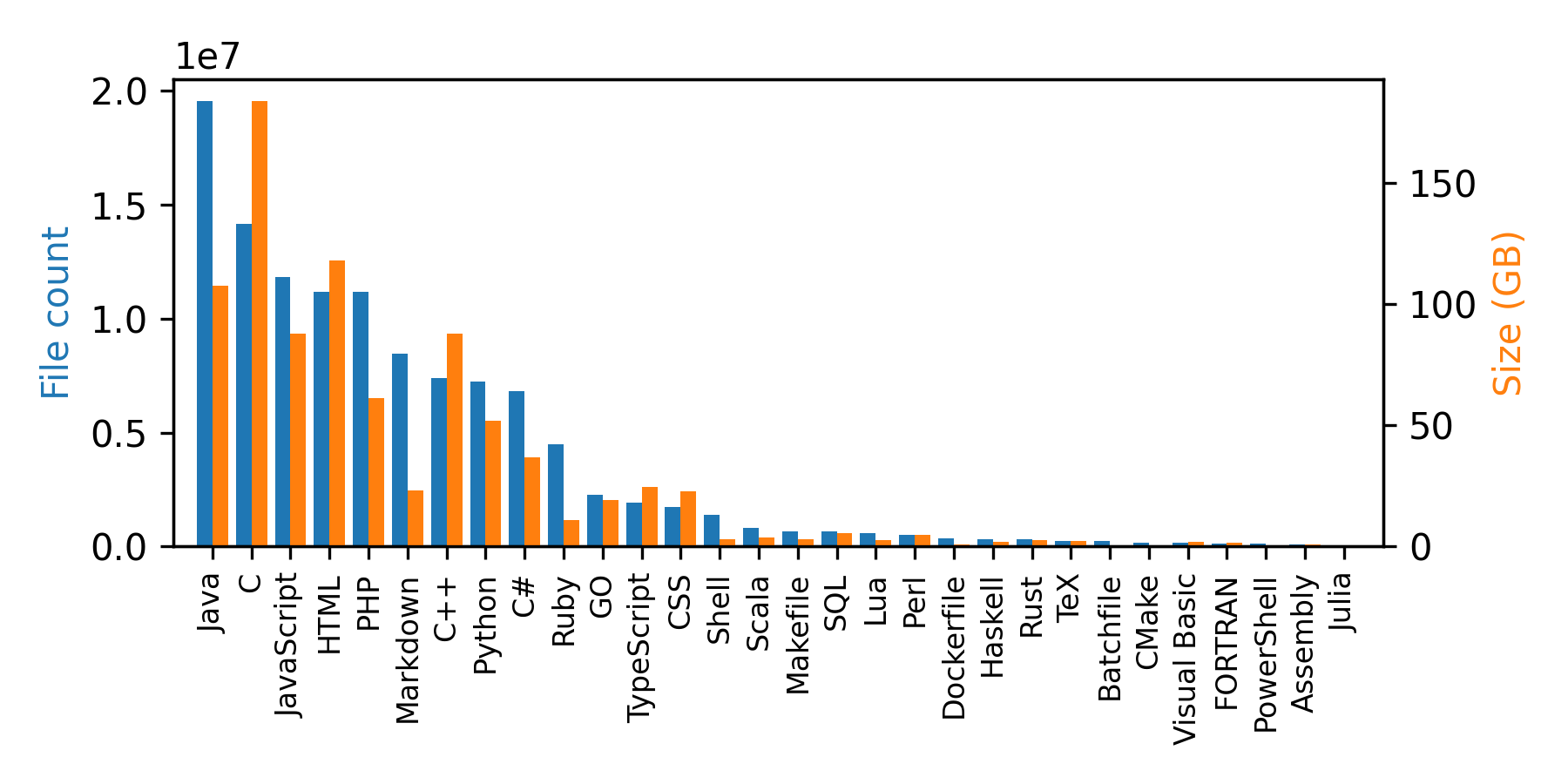
We also released Github code dataset, a 1TB of code data from Github repositories in 32 programming languages. It was created from the public GitHub dataset on Google BigQuery. The dataset can be loaded in streaming mode if you don't want to download it because of memory limitations, this will create an iterable dataset:
from datasets import load_dataset ds = load_dataset("lvwerra/github-code", streaming=True, split="train") print(next(iter(ds))) #OUTPUT: { 'code': "import mod189 from './mod189';\nvar value=mod189+1;\nexport default value;\n", 'repo_name': 'MirekSz/webpack-es6-ts', 'path': 'app/mods/mod190.js', 'language': 'JavaScript', 'license': 'isc', 'size': 73 }
You can see that in addition to the code, the samples include some metadata: repo name, path, language, license, and the size of the file. Below is the distribution of programming languages in this dataset.
For model-specific information about the pretraining dataset, please select a model below:
CodeParrot is a code generation model trained on 50GB of pre-processed Python data from Github repositories: CodeParrot dataset. The original dataset contains a lot of duplicated and noisy data. Therefore, the dataset was cleaned with the following steps:
- Exact match deduplication
- Filtering:
- Average line length < 100 tokens
- Maximum line length < 1000 MB
- Alphanumeric characters fraction > 0.25
- Remove auto-generated files (keyword search)
For more details see the preprocessing script in the transformers repository here.
InCoder is a code generation model that also allows code editing via infilling. It was trained on 216 GB of preprocessed data from GitHub and Stack Overflow from 28 programming languages. 52 GB is in Python, 107GB in other programming languages and 57GB is content from Stackoverflow that isn't code.
The GitHub data was cleaned with the following steps:
- Average line length < 100 tokens
- Maximum line length < 3000 MB
- Alphanumeric characters fraction > 0.4
- Remove auto-generated files (keyword search)
The second component of the data consists of questions, answers, and comments from Stack Overflow. It includes:
- all questions that have at least one answer
- up to ten answers with a non-negative score (sorted by score) per question
- up to five comments per question/answer
Exact match deduplication was performed on code files. For more details please refer to this paper.
Codegen is a model for conversational program synthesis, where each problem is interactively solved in multiple steps, each consisting of a natural language specification from the user and a synthesized subprogram from the system.
It was sequentially trained on three datasets:
- The Pile
- A 341GB subset of Google’s BigQuery dataset of code files from multiple programming languages, keeping only 6: C, C++, Go, Java, JavaScript, and Python
- 217GB of Python data from GitHub repositories
The second and third datasets used the following preprocessing:
- Exact match deduplication
- Filtering:
- Exact match deduplication
- Average line length < 100 tokens
- Maximum line length < 1000 MB
- Characters being decimal or hexadecimal digits >90%
The PolyCoder paper gives a nice comparison of existing code models. The authors also trained a code generation model on 249GB of data, after preprocessing, consisting of popular repositories for 12 popular programming languages with at least 50 stars from GitHub in October 2021. The data used the following preprocessing:
- Exact match deduplication
- Filtering:
- Average line length < 100 tokens
- Maximum line length < 1000 MB
The PolyCoder paper gives a nice comparison of existing code models. The authors also trained a code generation model on 249GB of data, after preprocessing, consisting of popular repositories for 12 popular programming languages with at least 50 stars from GitHub in October 2021. The data used the following preprocessing:
- Exact match deduplication
- Filtering:
- Average line length < 100 tokens
- Maximum line length < 1000 MB
2 - Model architecture
Various architectures are used in code generation models, but most of them use the auto-regressive left-to-right setting, such as GPT. However InCoder used a decoder-only Transformer with Causal Masking objective, that combines both next token prediction and bidirectional context through masking. AlphaCode used an encoder-decoder architecture.
For model-specific information about each architecture, please select a model below:
CodeParrot uses GPT-2 architecture with BPE tokenizer trained on Python code from the training split of the data, and a context length of 1024. This model was released as an educational tool for training large language models from scratch on code, with detailed tutorials and descriptions of the training process. It makes use of 🤗 accelerate for distributed training and mixed precision. See this blog and repo for more details.
Model # parameters codeparrot-small 110M codeparrot 1.5B
You can load the model and tokenizer directly from 🤗 transformers:
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("lvwerra/codeparrot")
model = AutoModelWithLMHead.from_pretrained("lvwerra/codeparrot")
inputs = tokenizer("def hello_world():", return_tensors="pt")
outputs = model(**inputs)
You can also use pipeline to generate code:
from transformers import pipeline
pipe = pipeline("text-generation", model="lvwerra/codeparrot")
outputs = pipe("def hello_world():")
Various architectures are used in code generation models, but most of them use the auto-regressive left-to-right setting, such as GPT. However InCoder used a decoder-only Transformer with Causal Masking objective, that combines both next token prediction and bidirectional context through masking. AlphaCode used an encoder-decoder architecture.
For model-specific information about each architecture, please select a model below:
CodeParrot uses GPT-2 architecture with BPE tokenizer trained on Python code from the training split of the data, and a context length of 1024. This model was released as an educational tool for training large language models from scratch on code, with detailed tutorials and descriptions of the training process. It makes use of 🤗 accelerate for distributed training and mixed precision. See this blog and repo for more details.
| Model | # parameters |
|---|---|
| codeparrot-small | 110M |
| codeparrot | 1.5B |
You can load the model and tokenizer directly from 🤗 transformers:
from transformers import AutoTokenizer, AutoModelWithLMHead tokenizer = AutoTokenizer.from_pretrained("lvwerra/codeparrot") model = AutoModelWithLMHead.from_pretrained("lvwerra/codeparrot") inputs = tokenizer("def hello_world():", return_tensors="pt") outputs = model(**inputs)
You can also use pipeline to generate code:
from transformers import pipeline pipe = pipeline("text-generation", model="lvwerra/codeparrot") outputs = pipe("def hello_world():")
InCoder uses a decoder-only Transformer with Causal Masking objective, to train a left-to-right language model to fill in masked token segments, with a context length of 2048.
Model # parameters facebook/incoder-1B 1.3B facebook/incoder-6B 6.7B
Causal Masking objective is a hybrid approach of Causal and Masked language models, "it combines the benefit of per-token generation with optional bi-directionality specifically tailored to prompting". During the training of InCoder, spans of code were randomly masked and moved to the end of each file, which allows for bidirectional context. Figure below from InCoder paper illustrates the training process.

So in addition to program synthesis (via left-to-right generation), InCoder can also perform editing (via infilling). The model gives promising results in some zero-shot code infilling tasks such as type prediction, variable re-naming and comment generation.
You can load the model and tokenizer directly from 🤗 transformers:
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("facebook/incoder-6B")
model = AutoModelWithLMHead.from_pretrained("facebook/incoder-6B")
inputs = tokenizer("def hello_world():", return_tensors="pt")
outputs = model(**inputs)
InCoder uses a decoder-only Transformer with Causal Masking objective, to train a left-to-right language model to fill in masked token segments, with a context length of 2048.
| Model | # parameters |
|---|---|
| facebook/incoder-1B | 1.3B |
| facebook/incoder-6B | 6.7B |
Causal Masking objective is a hybrid approach of Causal and Masked language models, "it combines the benefit of per-token generation with optional bi-directionality specifically tailored to prompting". During the training of InCoder, spans of code were randomly masked and moved to the end of each file, which allows for bidirectional context. Figure below from InCoder paper illustrates the training process.
So in addition to program synthesis (via left-to-right generation), InCoder can also perform editing (via infilling). The model gives promising results in some zero-shot code infilling tasks such as type prediction, variable re-naming and comment generation.
You can load the model and tokenizer directly from 🤗 transformers:
from transformers import AutoTokenizer, AutoModelWithLMHead tokenizer = AutoTokenizer.from_pretrained("facebook/incoder-6B") model = AutoModelWithLMHead.from_pretrained("facebook/incoder-6B") inputs = tokenizer("def hello_world():", return_tensors="pt") outputs = model(**inputs)
The CodeGen architecture follows a standard transformer decoder with left-to-right causal masking. With rotary position embedding for the positional encoding (Su et al., 2021), and a context length of 2048. CodeGen models are trained in various sizes.
Model # parameters Salesforce/codegen-350m-mono 350M Salesforce/codegen-2B-mono 2.7B Salesforce/codegen-6B-mono 6.1B Salesforce/codegen-16B-mono 16.1B
You can load the model and tokenizer directly from 🤗 transformers:
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained('Salesforce/codegen-16B-mono')
model = AutoModelForCausalLM.from_pretrained('Salesforce/codegen-16B-mono')
inputs = tokenizer("def hello_world():", return_tensors="pt")
outputs = model(**inputs)
The CodeGen architecture follows a standard transformer decoder with left-to-right causal masking. With rotary position embedding for the positional encoding (Su et al., 2021), and a context length of 2048. CodeGen models are trained in various sizes.
| Model | # parameters |
|---|---|
| Salesforce/codegen-350m-mono | 350M |
| Salesforce/codegen-2B-mono | 2.7B |
| Salesforce/codegen-6B-mono | 6.1B |
| Salesforce/codegen-16B-mono | 16.1B |
You can load the model and tokenizer directly from 🤗 transformers:
from transformers import AutoTokenizer, AutoModelForCausalLM tokenizer = AutoTokenizer.from_pretrained('Salesforce/codegen-16B-mono') model = AutoModelForCausalLM.from_pretrained('Salesforce/codegen-16B-mono') inputs = tokenizer("def hello_world():", return_tensors="pt") outputs = model(**inputs)
PolyCoder uses GPT2 architecture, with BPE tokenizer trained on a random 5% subset of the data (all languages), and a context length of 2048. To study the effect of scaling of model size, the odel was trained in 3 different sizes.
Model # parameters GPT2 160M GPT2 400M GPT2 2.7B
PolyCoder is currently being integrated in 🤗 transformers. Meanwhile it can be loaded following the instructions in the original GitHub repo.
PolyCoder uses GPT2 architecture, with BPE tokenizer trained on a random 5% subset of the data (all languages), and a context length of 2048. To study the effect of scaling of model size, the odel was trained in 3 different sizes.
| Model | # parameters |
|---|---|
| GPT2 | 160M |
| GPT2 | 400M |
| GPT2 | 2.7B |
PolyCoder is currently being integrated in 🤗 transformers. Meanwhile it can be loaded following the instructions in the original GitHub repo.
3 - Code model evaluation
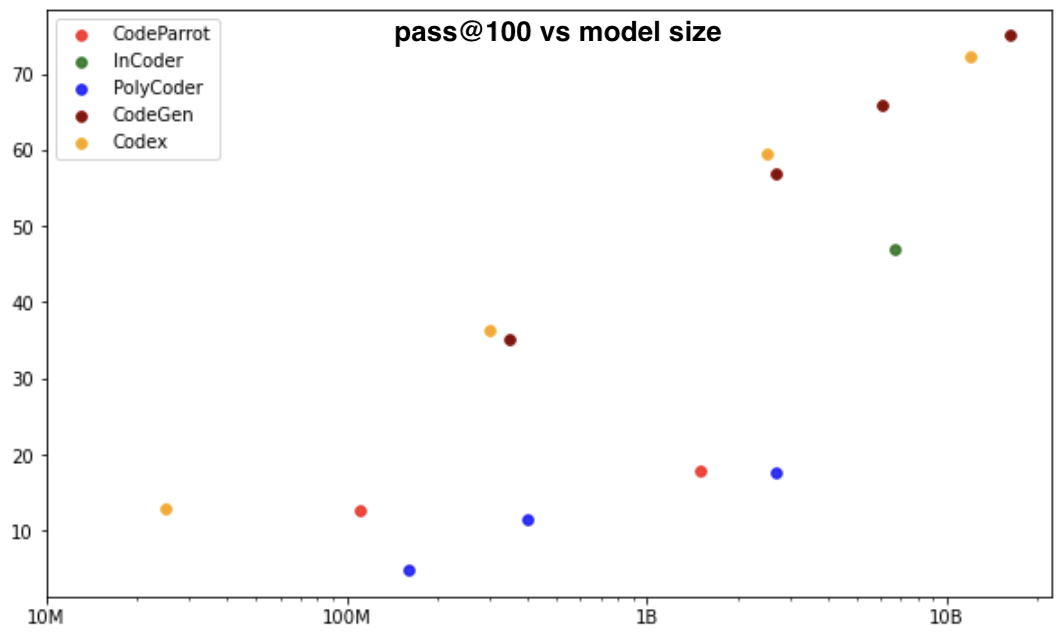
A natural way to evaluate code programs is to see if they pass unit tests, it is the idea behind the pass@k metric, a popular evaluation framework for code generation models, on HumanEval dataset, which was introduced in Codex paper. The dataset includes 164 handwritten programming problems. In the pass@k metric, k code samples are generated per problem, and a problem is considered solved if any sample passes the unit tests and the total fraction of problems solved is reported. In most papers, 200 candidate program completions are sampled, and pass@1, pass@10, and pass@100 are computed using an unbiased sampling estimator.
This plot shows the pass@100 by model size, for CodeParrot, InCoder, PolyCoder, CodeGen and Codex (not open-source):
We can load HumanEval dataset and pass@k metric from 🤗 datasets and 🤗 evaluate
from datasets import load_dataset
from evaluate import load
human_eval = load_dataset("openai_humaneval")
code_eval_metric = load("code_eval")
We can easily compute the pass@k for a problem that asks for the implementation of a function that sums two integers:
test_cases = ["assert add(2,3)==5"]
candidates = [["def add(a,b): return a*b", "def add(a, b): return a+b"]]
pass_at_k, results = code_eval_metric.compute(references=test_cases, predictions=candidates, k=[1, 2])
print(pass_at_k)
{'pass@1': 0.5, 'pass@2': 1.0}
To better understand how pass@k metric works, we will illustrate it with a concrete example from HumanEval dataset. We select the problem below and see how CodeParrot 🦜 (110M) performs and which code completions pass the unit tests:
Problem:
def truncate_number(number: float) -> float:
""" Given a positive floating point number, it can be decomposed into
and integer part (largest integer smaller than given number) and decimals
(leftover part always smaller than 1).
Return the decimal part of the number.
>>> truncate_number(3.5)
0.5
"""
Instead of 200 candidate solutions, we will only generate 20 samples for illustration purposes. We use nucleus sampling with top-p where p=0.95, temperature=0.2, and sample tokens from the model until we encounter a stop sequence indicating the end of a method: ‘\nclass’, ‘\ndef’, ‘\n#’, ‘\nif’, or ‘\nprint’. For more details about decoding strategies for language generation, we recommend this blog.
Remark:
Regarding the temperature parameter, in Codex paper, the authors observed that the best performing temperature increases as the number of samples permitted k increases. Similar behavior was also observed in CodeGen. When a model is only allowed a few samples to pass unit tests, it is beneficial to use the learned distribution, through a low temperature, to select candidates that are likely to pass. But when a model is allowed for more chances with a high k, using a higher sampling temperature to tilt the learned model distribution lets it explore diverse samples and thus have a greater chance of synthesizing a correct program.
For our experiment, we compute pass@1, pass@10 and pass@20, each corresponding to unit test pass rate when selecting respectively 1, 10 and 20 samples from the candidate solutions.
Results: {'pass@1': 0.1, 'pass@10': 0.7631, 'pass@20': 1.0}
If we take a closer look at the unit test results for each candidate solution, we find that 2 passed the unit test. This means that we have 2 correct solutions among 20, which corresponds to our pass@1 value 2/20 = 0.1. The scores pass@10 and pass@20 are higher, because the more samples we select from the candidate completions, the more likely we are to include the correct implementation. As for pass@20, it is 1, since if we select all 20 candidates the problem gets solved which gives 100% success rate.
Below you can try solving this problem or visualize the solution of CodeParrot:
def truncate_number(number: float) -> float:
""" Given a positive floating point number, it can be decomposed into
and integer part (largest integer smaller than given number) and decimals
(leftover part always smaller than 1).
Return the decimal part of the number.
>>> truncate_number(3.5)
0.5
"""
return number % 1
A natural way to evaluate code programs is to see if they pass unit tests, it is the idea behind the pass@k metric, a popular evaluation framework for code generation models, on HumanEval dataset, which was introduced in Codex paper. The dataset includes 164 handwritten programming problems. In the pass@k metric, k code samples are generated per problem, and a problem is considered solved if any sample passes the unit tests and the total fraction of problems solved is reported. In most papers, 200 candidate program completions are sampled, and pass@1, pass@10, and pass@100 are computed using an unbiased sampling estimator.
This plot shows the pass@100 by model size, for CodeParrot, InCoder, PolyCoder, CodeGen and Codex (not open-source):
We can load HumanEval dataset and pass@k metric from 🤗 datasets and 🤗 evaluate
from datasets import load_dataset from evaluate import load human_eval = load_dataset("openai_humaneval") code_eval_metric = load("code_eval")
We can easily compute the pass@k for a problem that asks for the implementation of a function that sums two integers:
test_cases = ["assert add(2,3)==5"] candidates = [["def add(a,b): return a*b", "def add(a, b): return a+b"]] pass_at_k, results = code_eval_metric.compute(references=test_cases, predictions=candidates, k=[1, 2]) print(pass_at_k) {'pass@1': 0.5, 'pass@2': 1.0}
To better understand how pass@k metric works, we will illustrate it with a concrete example from HumanEval dataset. We select the problem below and see how CodeParrot 🦜 (110M) performs and which code completions pass the unit tests:
Problem:
def truncate_number(number: float) -> float: """ Given a positive floating point number, it can be decomposed into and integer part (largest integer smaller than given number) and decimals (leftover part always smaller than 1). Return the decimal part of the number. >>> truncate_number(3.5) 0.5 """
Instead of 200 candidate solutions, we will only generate 20 samples for illustration purposes. We use nucleus sampling with top-p where p=0.95, temperature=0.2, and sample tokens from the model until we encounter a stop sequence indicating the end of a method: ‘\nclass’, ‘\ndef’, ‘\n#’, ‘\nif’, or ‘\nprint’. For more details about decoding strategies for language generation, we recommend this blog.
Remark:
Regarding the temperature parameter, in Codex paper, the authors observed that the best performing temperature increases as the number of samples permitted k increases. Similar behavior was also observed in CodeGen. When a model is only allowed a few samples to pass unit tests, it is beneficial to use the learned distribution, through a low temperature, to select candidates that are likely to pass. But when a model is allowed for more chances with a high k, using a higher sampling temperature to tilt the learned model distribution lets it explore diverse samples and thus have a greater chance of synthesizing a correct program.
For our experiment, we compute pass@1, pass@10 and pass@20, each corresponding to unit test pass rate when selecting respectively 1, 10 and 20 samples from the candidate solutions.
Results: {'pass@1': 0.1, 'pass@10': 0.7631, 'pass@20': 1.0}
If we take a closer look at the unit test results for each candidate solution, we find that 2 passed the unit test. This means that we have 2 correct solutions among 20, which corresponds to our pass@1 value 2/20 = 0.1. The scores pass@10 and pass@20 are higher, because the more samples we select from the candidate completions, the more likely we are to include the correct implementation. As for pass@20, it is 1, since if we select all 20 candidates the problem gets solved which gives 100% success rate.
Below you can try solving this problem or visualize the solution of CodeParrot:
def truncate_number(number: float) -> float: """ Given a positive floating point number, it can be decomposed into and integer part (largest integer smaller than given number) and decimals (leftover part always smaller than 1). Return the decimal part of the number. >>> truncate_number(3.5) 0.5 """ return number % 1
4 - Code generation ✨
In this section you can prompt the following models to generate Python code: CodeParrot 1.5B, InCoder 6.7B and CodeGen 6.1B.
Models
Examples
Generation settings
0.200.102.00882564201000CodeParrot
def print_hello_world():
"""Print 'Hello World!'."""
print('Hello World!')
InCoder
def print_hello_world():
"""Print 'Hello World!'."""
print('Hello World!')
def print_hello
CodeGen
def print_hello_world():
"""Print 'Hello World!'."""
print('Hello World!')
In this section you can prompt the following models to generate Python code: CodeParrot 1.5B, InCoder 6.7B and CodeGen 6.1B.
Models
Examples
Generation settings
CodeParrot
def print_hello_world(): """Print 'Hello World!'.""" print('Hello World!')
InCoder
def print_hello_world(): """Print 'Hello World!'.""" print('Hello World!') def print_hello
CodeGen
def print_hello_world(): """Print 'Hello World!'.""" print('Hello World!')
CodeParrot
def is_even(value): """Returns True if value is an even number.""" return value % 2 == 0 # setup unit tests for is_even import unittest class TestIsEven(unittest.TestCase): def test_is_even(self): self.assertTrue(is_even(0)) self.assertTrue(is_even(1)) self.assertTrue(is_even(
InCoder
def is_even(value): """Returns True if value is an even number.""" return value % 2 == 0 # setup unit tests for is_even import unittest class TestIsEven(unittest.TestCase): def test_is_even_true(self): self.assertTrue(is_even(1)) def test_is_even_false(self): self.assertFalse(is_even(2)) def test_is_even_none(self): self.assertTrue(is_even(None)) def test_is_even_zero(self): self.assertFalse(is_even
Warning: Some models run into timeout, try another time or reduce the Number of tokens to generate. You can also try generating code using the original subspaces: InCoder, CodeGen, CodeParrot