is a 12-billion parameter version ofGPT-3 trained to generate images from text descriptions, using a dataset of
text–image pairs. We’ve found that it has a diverse set of capabilities,
including creating anthropomorphized versions of animals and objects,
combining unrelated concepts in plausible ways, rendering text, and
applying transformations to existing images.
Text prompt
an illustration of a baby daikon radish in a tutu walking a dog
GPT-3 showed that language can be used to instruct a large neural network to perform a variety of text generation tasks. Image GPT showed that the same type of neural network can also be used to
generate images with high fidelity. We extend these findings to show
that manipulating visual concepts through language is now within reach.
Overview
Like GPT-3, DALL·E is a transformer language model. It receives both
the text and the image as a single stream of data containing up to 1280
tokens, and is trained using maximum likelihood to generate all of the
tokens, one after another.[2]
This training procedure
allows DALL·E to not only generate an image from scratch, but also to
regenerate any rectangular region of an existing image that extends to
the bottom-right corner, in a way that is consistent with the
text prompt.
We recognize that work involving generative models has the potential
for significant, broad societal impacts. In the future, we plan to
analyze how models like DALL·E relate to societal issues like economic
impact on certain work processes and professions, the potential for bias
in the model outputs, and the longer term ethical challenges implied by
this technology.
Capabilities
We find that DALL·E is able to create plausible images for a great
variety of sentences that explore the compositional structure of
language. We illustrate this using a series of interactive visuals in
the next section. The samples shown for each caption in the visuals are
obtained by taking the top 32 of 512 after reranking with CLIP, but we do not use any manual cherry-picking, aside from the thumbnails and standalone images that appear outside.[3]
Controlling Attributes
We test DALL·E’s ability to modify several of an object’s attributes, as well as the number of times that it appears.
Click to edit text prompt or view more AI-generated images
a pentagonal green clock. a green clock in the shape of a pentagon.
navigatedownwide
a cube made of porcupine. a cube with the texture of a porcupine.
navigatedownwide
a collection of glasses is sitting on a table
navigatedownwide
Drawing Multiple Objects
Simultaneously controlling multiple objects, their attributes, and
their spatial relationships presents a new challenge. For example,
consider the phrase “a hedgehog wearing a red hat, yellow gloves, blue
shirt, and green pants.” To correctly interpret this sentence, DALL·E
must not only correctly compose each piece of apparel with the animal,
but also form the associations (hat, red), (gloves, yellow), (shirt,
blue), and (pants, green) without mixing them up.[4]
We test DALL·E’s ability to do this for relative positioning, stacking objects, and controlling multiple attributes.
a small red block sitting on a large green block
navigatedownwide
a stack of 3 cubes. a red cube is on the top, sitting on a green cube.
the green cube is in the middle, sitting on a blue cube. the blue cube
is on the bottom.
navigatedownwide
an emoji of a baby penguin wearing a blue hat, red gloves, green shirt, and yellow pants
navigatedownwide
While DALL·E does offer some level of controllability over the
attributes and positions of a small number of objects, the success rate
can depend on how the caption is phrased. As more objects are
introduced, DALL·E is prone to confusing the associations between the
objects and their colors, and the success rate decreases sharply. We
also note that DALL·E is brittle with respect to rephrasing of the
caption in these scenarios: alternative, semantically equivalent
captions often yield no correct interpretations.
Visualizing Perspective and Three-Dimensionality
We find that DALL·E also allows for control over the viewpoint of a scene and the 3D style in which a scene is rendered.
an extreme close-up view of a capybara sitting in a field
navigatedownwide
a capybara made of voxels sitting in a field
navigatedownwide
To push this further, we test DALL·E’s ability to repeatedly draw the
head of a well-known figure at each angle from a sequence of equally
spaced angles, and find that we can recover a smooth animation of the
rotating head.
a photograph of a bust of homer
navigatedownwide
DALL·E appears to be able to apply some types of optical distortions
to scenes, as we see with the options “fisheye lens view” and “a
spherical panorama.” This motivated us to explore its ability to
generate reflections.
a plain white cube looking at its own reflection in a mirror. a plain white cube gazing at itself in a mirror.
navigatedownwide
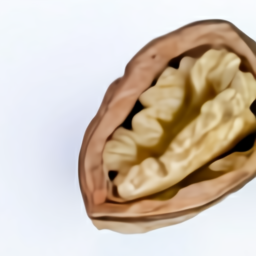
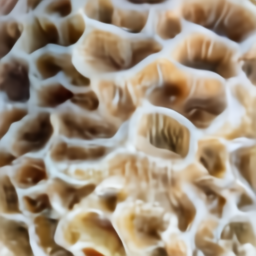
Visualizing Internal and External Structure
The samples from the “extreme close-up view” and “x-ray” style led us
to further explore DALL·E’s ability to render internal structure with
cross-sectional views, and external structure with macro photographs.
a cross-section view of a walnut
navigatedownwide
a macro photograph of brain coral
navigatedownwide
Inferring Contextual Details
The task of translating text to images is underspecified: a single
caption generally corresponds to an infinitude of plausible images, so
the image is not uniquely determined. For instance, consider the caption
“a painting of a capybara sitting on a field at sunrise.” Depending on
the orientation of the capybara, it may be necessary to draw a shadow,
though this detail is never mentioned explicitly. We explore DALL·E’s
ability to resolve underspecification in three cases: changing style,
setting, and time; drawing the same object in a variety of different
situations; and generating an image of an object with specific text
written on it.
a painting of a capybara sitting in a field at sunrise
navigatedownwide
a stained glass window with an image of a blue strawberry
navigatedownwide
a store front that has the word ‘openai’ written on it. a store front
that has the word ‘openai’ written on it. a store front that has the
word ‘openai’ written on it. ‘openai’ store front.
navigatedownwide
With varying degrees of reliability, DALL·E provides access to a
subset of the capabilities of a 3D rendering engine via natural
language. It can independently control the attributes of a small number
of objects, and to a limited extent, how many there are, and how they
are arranged with respect to one another. It can also control the
location and angle from which a scene is rendered, and can generate
known objects in compliance with precise specifications of angle and
lighting conditions.
Unlike a 3D rendering engine, whose inputs must be specified
unambiguously and in complete detail, DALL·E is often able to “fill in
the blanks” when the caption implies that the image must contain a
certain detail that is not explicitly stated.
Applications of Preceding Capabilities
Next, we explore the use of the preceding capabilities for fashion and interior design.
a male mannequin dressed in an orange and black flannel shirt
navigatedownwide
a female mannequin dressed in a black leather jacket and gold pleated skirt
navigatedownwide
a living room with two white armchairs and a painting of the colosseum. the painting is mounted above a modern fireplace.
navigatedownwide
a loft bedroom with a white bed next to a nightstand. there is a fish tank beside the bed.
navigatedownwide
Combining Unrelated Concepts
The compositional nature of language allows us to put together
concepts to describe both real and imaginary things. We find that DALL·E
also has the ability to combine disparate ideas to synthesize objects,
some of which are unlikely to exist in the real world. We explore this
ability in two instances: transferring qualities from various concepts
to animals, and designing products by taking inspiration from
unrelated concepts.
a snail made of harp. a snail with the texture of a harp.
navigatedownwide
an armchair in the shape of an avocado. an armchair imitating an avocado.
navigatedownwide
Animal Illustrations
In the previous section, we explored DALL·E’s ability to combine
unrelated concepts when generating images of real-world objects. Here,
we explore this ability in the context of art, for three kinds of
illustrations: anthropomorphized versions of animals and objects, animal
chimeras, and emojis.
an illustration of a baby daikon radish in a tutu walking a dog
navigatedownwide
a professional high quality illustration of a giraffe turtle chimera. a giraffe imitating a turtle. a giraffe made of turtle.
navigatedownwide
a professional high quality emoji of a lovestruck cup of boba
navigatedownwide
Zero-Shot Visual Reasoning
GPT-3 can be instructed to perform many kinds of tasks solely from a
description and a cue to generate the answer supplied in its prompt,
without any additional training. For example, when prompted with the
phrase “here is the sentence ‘a person walking his dog in the park’
translated into French:”, GPT-3 answers “un homme qui promène son chien
dans le parc.” This capability is called zero-shot reasoning. We find that DALL·E extends this capability to the visual domain, and is
able to perform several kinds of image-to-image translation tasks when
prompted in the right way.
the exact same cat on the top as a sketch on the bottom
navigatedownwide
the exact same teapot on the top with ’gpt’ written on it on the bottom
navigatedownwide
We did not anticipate that this capability would emerge, and made no
modifications to the neural network or training procedure to encourage
it. Motivated by these results, we measure DALL·E’s aptitude for
analogical reasoning problems by testing it on Raven’s progressive
matrices, a visual IQ test that saw widespread use in the 20th century.
a sequence of geometric shapes.
navigatedownwide
Geographic Knowledge
We find that DALL·E has learned about geographic facts, landmarks,
and neighborhoods. Its knowledge of these concepts is surprisingly
precise in some ways and flawed in others.
a photo of the food of china
navigatedownwide
a photo of alamo square, san francisco, from a street at night
navigatedownwide
a photo of san francisco’s golden gate bridge
navigatedownwide
Temporal Knowledge
In addition to exploring DALL·E’s knowledge of concepts that vary
over space, we also explore its knowledge of concepts that vary
over time.
a photo of a phone from the 20s
navigatedownwide
Summary of Approach and Prior Work
DALL·E is a simple decoder-only transformer that receives both the
text and the image as a single stream of 1280 tokens—256 for the text
and 1024 for the image—and models all of them autoregressively. The
attention mask at each of its 64 self-attention layers allows each image
token to attend to all text tokens. DALL·E uses the standard causal
mask for the text tokens, and sparse attention for the image tokens with
either a row, column, or convolutional attention pattern, depending on
the layer. We provide more details about the architecture and training
procedure in our paper.
Text-to-image synthesis has been an active area of research since the pioneering work of Reed et. al,1 whose approach uses a GAN conditioned on text embeddings. The
embeddings are produced by an encoder pretrained using a contrastive
loss, not unlike CLIP. StackGAN3 and StackGAN++4 use multi-scale GANs to scale up the image resolution and improve visual fidelity. AttnGAN5 incorporates attention between the text and image features, and
proposes a contrastive text-image feature matching loss as an auxiliary
objective. This is interesting to compare to our reranking with CLIP,
which is done offline. Other work267 incorporates additional sources of supervision during training to improve image quality. Finally, work by Nguyen et. al8 and Cho et. al9 explores sampling-based strategies for image generation that leverage pretrained multimodal discriminative models.
Similar to the rejection sampling used in VQVAE-2, we use CLIP to rerank the top 32 of 512 samples for each caption in all of the
interactive visuals. This procedure can also be seen as a kind of
language-guided search16, and can have a dramatic impact on sample quality.
an illustration of a baby daikon radish in a tutu walking a dog [caption 1, best 8 of 2048]